5 things I wish I knew before starting with Firebase's Cloud Firestore
8 mei 2024
In my experience using Firestore as a database solution, I've had to learn at the same time as being productive. I've learned the following lessons the hard way while building and maintaining a multi-tenant web application with challenging features like role-based authorization and version management. If you get these right from the start, you could save yourself a lot of time and headaches.
1. Prioritize hierarchical database design
Firestore is a NoSQL database. One of the fundamental shifts in mindset when working with Firestore is embracing hierarchical data structures over traditional relational models. Unlike SQL databases where you might use tables and foreign keys to establish relationships between entities, Firestore encourages organizing data hierarchically into collections and subcollections.
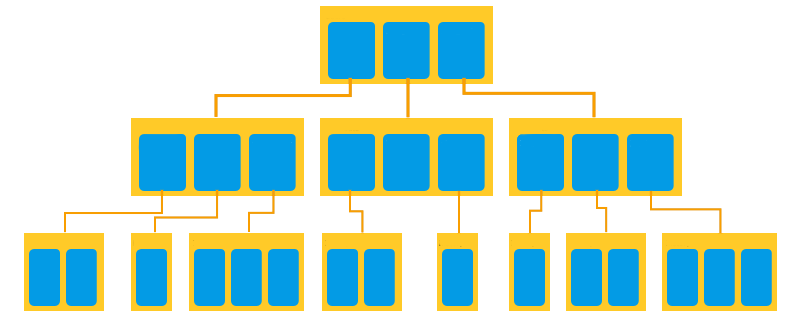
This is a scalable, intuitive approach that simplifies querying. In practice, you'll find it's not that much different from a typical relation in a Relational database management system. I mean, it's still a relation, just a different kind!
The benefits of using subcollections
The data will resemble the hierarchy of the actual UI, which reduces the cognitive complexity of designing a database. The queries are also very easy to write and readable. There are a few other advantages:
You can go deeper
You can have subcollections inside subcollections. And subcollections inside subcollections inside subcollections. Hehe, you get the gist. Take for example, a Reddit-like application where you have a posts collection with a comments subcollection. Each comment could have a replies subcollection and those replies could have another replies subcollection. You can go as deep as you want.

Easier, granular authorization
You'll have more control over your authorization logic. The security rules of your subcollection will be easier to write, and can be different from the parent collection. For example, a product review subcollection might only be accessible to users who have purchased the product. The product itself might be accessible to all users. If the review was a separate collection, you'd have to write more complex security rules.
Collection group queries
You can query a collection and all its subcollections at once. This is called a collection group query. This is allows you to search for documents within all collections of a specified name, regardless of their hierarchy. Powerful, isn't it? See the next point for more on this.
Is hierarchical data always better?
Rather than flattening your data model, consider structuring it hierarchically. So should you never flatten your data model? Not at all! It's all about finding the right balance between normalization and denormalization. Figure out the right fit for your use case. I recommend the following videos and documentation to get an even better understanding of this concept:
- Docs: Firestore Data Model
- Video: Maps, Arrays and Subcollections, Oh My!
- Video: How to Structure Your Data
2. You can query through multiple subcollections.
This one didn't even exist when I started with Firestore, and oh boy did I need it. Subcollections are useful, sure, but what if we want to query data across multiple subcollections with the same name? With Collection Group Queries you can search for documents within all collections of a specified name, regardless of their hierarchy. So let's say you want to query all reviews across all products: You can do this with a collection group query.
Whether you're building a complex multi-tenant app or simply need to aggregate some data, you're going to need this at some point. Read more on this here: Understanding Collection Group Queries.
3. It's okay to have duplication in your database
Relational SQL purists be like

I can feel you cringing already. But hear me out...
Firestore is optimized for reading data
Users of your app usually do a lot more reading than saving of data. For this reason, duplication of data is not only acceptable but often encouraged. Unlike traditional SQL databases where normalization is preferred to minimize redundancy, Firestore prioritizes optimizing read operations over write operations.
With duplication being acceptable, you can design more complex write operations without worrying excessively about performance implications. This may seem counterintuitive compared to traditional database design principles, so here are the main advantages:
- Reading operations will be faster because you don't have to fetch data from multiple tables or collections. If you don't believe how fast Firestore can be, remember that Firestore is a real-time database by default!
- Writing read operations (and you'll have way more of those) will be easier because all the data you need is already there in the document.
Example: Chat application
Let's say you're building a chat application. You could have a users collection and a messages collection. Each message document could contain the user's name and profile picture. This way, you don't have to fetch the user's data from the users collection every time you fetch a message.
The downsides of duplication
We can't ignore the caveats:
- Your create, update and delete operations will be more complex and you'll have to be careful to keep the duplicated data in sync. But that's okay as well. More on this in the next point.
- Database migrations, because of an architectural change, will be more complex. It doesn't help that Firestore doesn't have a built-in migration tool. This is, in my opinion, the biggest downside.
- More data storage. This is usually not a problem because Firestore is very affordable.
4. It's also okay to have complicated write operations
You need to be careful with creating, updating and deleting data. If you have duplicated data and you need to update it, you need to make sure you update all instances of the data. This can be done with batched writes or transactions.
Coding write operations be like

I'm sorry! Some sacrifice has to be made to keep read operations simple and swift. You'll notice that writing the code for a create, update or delete operation will cost you more time and effort than that of a read. I've spent a lot of time writing code that updates multiple documents across different collections in a batch. And I've had moments where I thought:
"Am I still doing the right thing? Should I have picked SQL instead?"
Cast aside those doubts! You're optimizing for read operations. Just have a look at how simple the code is in your read operations and how fast they perform. Also, you won't have to do code write operations nearly as much as reads. It's worth it!
Coding read operations be like

5. Use the Firebase CLI
Don't be like me, who for a long time just edited security rules in the Firebase console. You can't track changes through git, and it's just not as nice as editing code in your favorite editor. With the Firebase CLI, you can manage your security rules as code, enabling version control, collaboration, and automation. Read more on this here: Firebase CLI.
I can also recommend this VSCode extension Firestore Rules that gives you syntax highlighting and autocompletion for Firestore security rules. Here's a webstorm alternative: Firestore Rules Webstorm.
Note: You can also use the Firebase CLI to deploy functions, hosting, and more.
I hope that was helpful
Hopefully these points were insightful and will make you more confident in your technical approach using Firestore. If you have any questions or want to share your experience, feel free to reach out to me.